Different Levels of Data and Process Distribution
Current database systems can be classified on the basis of how process distribution and data distribution are supported.
For example, a DBMS may store data in a single site (centralized DB) or in multiple sites (distributed DB) and may support data processing at a single site or at multiple sites. The different types of Data and Process distribution methods are as follows.
You May Also Like:
Distributed Processing and Distributed Databases
Advantages and Disadvantages of DDBMS
Single-Site Processing, Single-Site Data (SPSD):
In the single-site processing, single-site data (SPSD) scenario, all processing is done on a single host computer (single-processor server, multiprocessor server, mainframe system) and all data are stored on the host computer’s local disk system. Processing cannot be done on the end user’s side of the system. Such a scenario is typical of most mainframe and midrange server computer DBMSs. The DBMS is located on the host computer, which is accessed by dumb terminals connected to it.
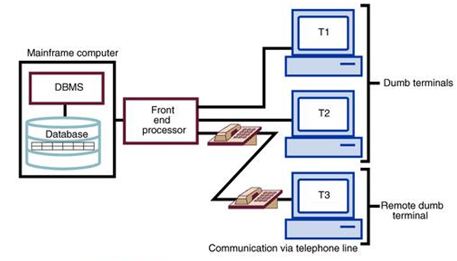
In the above figure you can see that the functions of the TP and the DP are embedded within the DBMS located on a single computer. The DBMS usually runs under a time-sharing, multitasking operating system, which allows several processes to run concurrently on a host computer accessing a single DP. All data storage and data processing are handled by a single host computer.
Multiple-Site Processing, Single-Site Data (MPSD):
Under the multiple-site processing, single-site data (MPSD) scenario, multiple processes run on different computers sharing a single data repository. Typically, the MPSD scenario requires a network file server running conventional applications that are accessed through a network. Many multiuser accounting applications running under a personal computer network fit such a description. Consider the following figure.
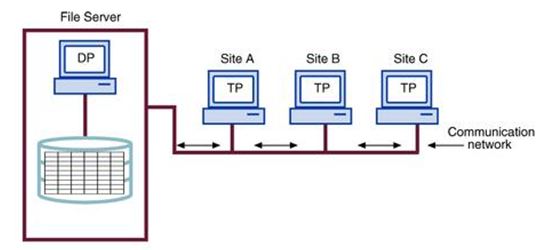
As you examine in the above Figure, Note that:
• The TP on each workstation acts only as a redirector to route all network data requests to the file server.
• The end user sees the file server as just another hard disk. Because only the data storage input/output (I/O) is handled by the file server’s computer, the MPSD offers limited capabilities for distributed processing.
• The end user must make a direct reference to the file server in order to access remote data. All record- and file-locking activities are done at the end-user location.
• All data selection, search, and update functions take place at the workstation, thus requiring that entire files travel through the network for processing at the workstation. Such a requirement increases network traffic, slows response time, and increases communication costs.
Multiple-Site Processing, Multiple-Site Data (MPMD):
• The multiple-site processing, multiple-site data (MPMD) scenario describes a fully distributed DBMS with support for multiple data processors and transaction processors at multiple sites. Depending on the level of support for various types of centralized DBMSs, DDBMSs are classified as either homogeneous or heterogeneous..
• Homogeneous DDBMSs integrate only one type of centralized DBMS over a network. Thus, the same DBMS will be running on different server platforms (single processor server, multiprocessor server, server farms, or server blades). In contrast, heterogeneous DDBMSs integrate different types of centralized DBMSs over a network. A fully heterogeneous DDBMS will support different DBMSs that may even support different data models (relational, hierarchical, or network) running under different computer systems, such as mainframes and PCs.
You May Also Like:
Distributed Database Design Concepts
Different Types of Distribution Transparency
